DISTRIBUSI FREKUENSI
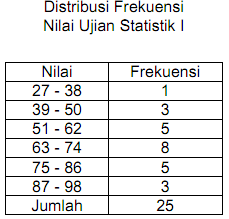
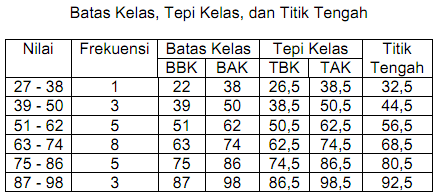
Salah satu cara untuk mendeskripsikan data mentah adalah dengan menyusunnya kedalam tabel distribusi frekuensi. Dengan tabel distribusi frekuensi ini, orang akan lebih mudah memahami gambaran data, karena data mentah tersebut sudah dikelompok-kelompokkan berdasarkan pengelompokkan tertentu.
Salah satu software statistik yang menurut saya cukup bagus dalam menyusun tabel distribusi frekuensi ini adalah Program SPSS. Meskipun demikian, di Excel kita juga menyusun tabel distribusi frekuensi dari data mentah dengan cara yang relatif mudah.
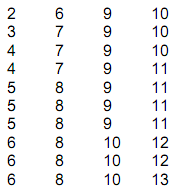
Untuk latihan, misalnya kita punya data umur dari hasil survai terhadap 20 orang responden (hanya untuk menyederhanakan, dalam prakteknya ini akan lebih bermanfaat kalau data mentahnya banyak) sebagai berikut:
20 18 25 30 34 32 35 17 22 21 38 17 28 30 35 36 32 22 30 32
Tempatkan data kita ini mulai pada sel A2 sampai A21 (range A2:A21).
Selanjutnya, misalnya kita ingin mengelompokkan atas kelompok umur sebagai berikut:
<= 19
20 – 24
25 – 29
30 – 34
35 – 39
Ketikkan angka 19, 24, 29, 34, 39 berturut-turut pada kolom C mulai dari sel C2 sampai C6 (range C2:C6).
Setelah itu, di sel D2 ketikkan rumus berikut: =FREQUENCY(A2:A21,C2:C6). Setelah itu, blok range dari D2:D6, kemudian tekan F2 dan tekan CTRL+SHIFT+ENTER bersamaan. Maka hasil distribusi frekuensi kita akan muncul pada range D2:D6. Kita juga bisa menambahkan persentase di kolom berikutnya. Jumlahkan terlebih dahulu distribusi frekuensi tersebut dan tempatkan jumlahnya pada sel D7. Kemudian pada sel E2 ketikkan rumus berikut: =(D2/D$7)*100. Selanjutnya, copy rumus tersebut sampai pada sel E6.
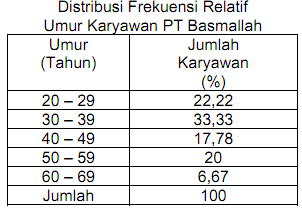
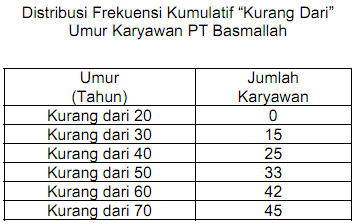
Hasil pekerjaan kita, terlihat pada tampilan berikut:
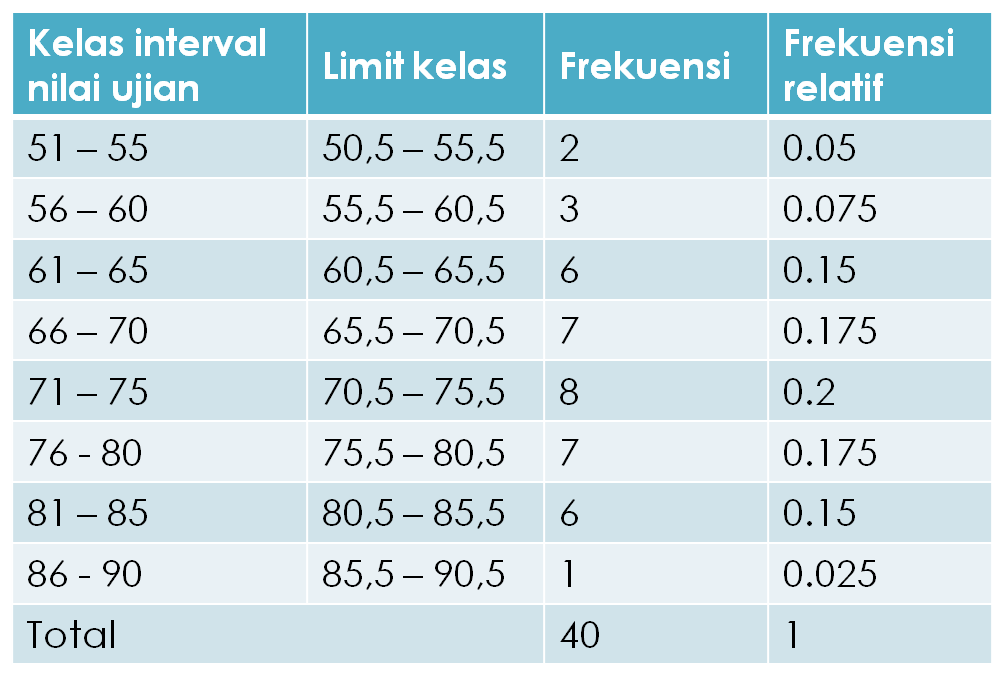
1. Dari tampilan tersebut dapat dikemukakan bahwa yang berumur 19 tahun atau kurang sebanyak 2 orang, antara 20 – 24 tahun sebanyak 4 orang, antara 25 – 29 tahun sebanyak 2 orang, dan seterusnya.
2. Jumlahnya sebanyak 20 orang. Selanjutnya di kolom E, dapat kita baca bahwa yang berumur 19 tahun atau kurang sebesar 15,00 persen dari keseluruhan responden, yang berumur 24 – 29 tahun sebesar 20,00 persen dan seterusnya.
HISTOGRAM DENGAN MS AXCEL
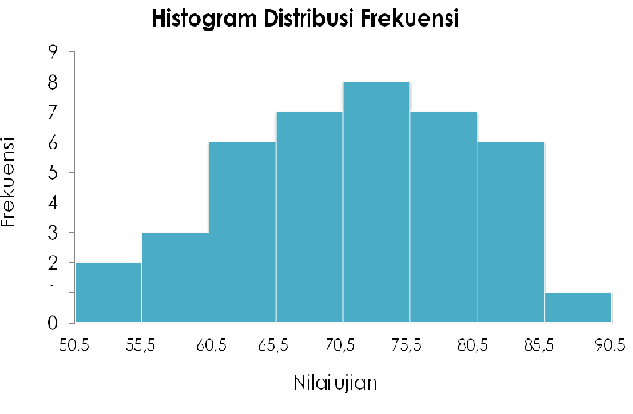
Histogram adalah grafik kolom yang menampilkan data frekuensi. Untuk menggunakan sarana histogram di Excel, Anda harus menyusun data Anda menjadi dua kolom di lembar kerja: satu kolom untuk data masukan dan kolom yang lain untuk angka bin. Data masukan adalah data yang ingin Anda analisis. Angka bin melambangkan interval yang ingin digunakan dalam toolhistogram untuk mengukur dan menganalisis data masukan.
1. MEMASANG ANALYSIS TOOLPACK ADD-INNUNTUK EXCEL 2010 DAN 2013
=> Pastikan bahwa add-in sudah terpasang. Sebelum Anda dapat menggunakan tool histogram di Microsoft Excel, Anda harus memastikan bahwa Analysis ToolPak Add-in sudah siap digunakan.
=> Bukalah kotak dialog Excel Add-ins. Anda dapat melakukannya dari layar utama Home setelah Anda membuka program.
- Klik Options di menu File.
- Kemudian, klik Add-Ins pada panel navigasi.
- Pada daftar Manage, pilihlah Excel Add-ins. Kemudian, klik Go.
=> Pilihlah Analysis ToolPak Add-in. Setelah Anda membuka kotak dialog Add-Ins, pilihlah kotak centang Analysis ToolPak di bawah Add-Ins available, jika belum dicentang. Kemudian, klik OK.
- Perhatikan bahwa Analysis ToolPak Add-in tidak akan muncul di kotak dialog Add-Ins jika tool ini belum terpasang di komputer Anda. Jika Anda tidak melihat Analysis ToolPak di kotak dialog Add-Ins, jalankan Microsoft Excel Setup. Tambahkan ToolPak ke daftar tool yang terpasang.
2. MEMASANG ANALYSIS TOOLPAK ADD-IN UNTUK EXCEL 2010 DAN 2013
=> Bukalah kotak dialog Excel Add-ins. Inilah tempat Anda dapat memeriksa apakah Analysis ToolPak sudah terpasang di komputer Anda.
- Dari layar Home, klik tombol Microsoft Office. Kemudian, pilih Excel Options.
- Klik Add-Ins dari panel navigasi.
- Pilih Excel Add-ins dari daftar Manage. Kemudian, klik Go.
=> Pilih ToolPak. Di kotak dialog Add-Ins, pastikan bahwa kotak centang Analysis ToolPak di bawah Add-Ins available telah dipilih. Kemudian, klik OK. Ini akan mengaktifkan Analysis ToolPak—dan fungsi histogram— di komputer Anda.
3. MEMBUAT HISTOGRAM
=> Masukkan data Anda. Susunlah data Anda menjadi dua kolom yang berdekatan di lembar kerja. Isilah kolom kirinya dengan “data masukan” Anda dan kolom kanannya dengan “angka bin” Anda.
- Data masukan adalah sekumpulan angka yang ingin Anda analisis menggunakan tool histogram.
- Angka bin melambangkan interval yang ingin digunakan dalam tool histogram untuk mengukur dan menganalisis data masukan. Misalnya, jika Anda ingin memisahkan nilai menggunakan kategori A, B, C, D, dan F, Anda dapat membuat bin untuk 60, 70, 80, 90, dan 100
=> Bukalah kotak Data Analysis. Proses ini sama untuk semua versi Excel yang dikeluarkan sejak tahun 2007. Jika Anda menggunakan versi perangkat lunak sebelumnya, Anda harus mengikuti proses yang sedikit berbeda.
- Di Excel 2013, Excel 2010, dan Excel 2007: bukalah tab Data. Kemudian, klik Data Analysis di kelompok Analysis.
- Untuk Excel 2003 dan versi sebelumnya: pilihlah Data Analysis dari menu Tools. Jika tidak ada pilihan Data Analysis di menu Tools, Anda mungkin harus memasang add-in.
=> Pilih Histogram. Setelah Anda membuka kotak dialog Data Analysis, carilah Histogram di antara tool analisis lainnya. Kemudian, klik OK. Ini akan membuka kotak dialog Histogram.
=> Pilihlah rentang masukan dan rentang bin. Rentang masukan adalah rentang sel yang memiliki data. Jika data masukan Anda berupa sepuluh angka, dan Anda sudah menyalinnya ke kolom A (dari A1 hingga A10), masukkan rentang data Anda sebagai A1:A10. Rentang bin adalah rentang sel yang berisi angka bin Anda. JIka Anda memiliki empat bin di atas kolom B, masukkan rentang bin Anda sebagai B1:B4.
=> Berilah centang pada kotak keluaran grafik. Di bagian Output Options, klik New Workbook. Kemudian, pilih kotak centang Chart Output.
=> Klik OK untuk menyelesaikan proses. Excel akan membuat lembar kerja baru dengan tabel histogram dan grafik tambahan. Grafik ini berupa grafik kolom yang menyusun data dari tabel histogram Anda